Building A Serverless Event-Driven Pipeline That Boosts Your AWS Monitoring Efforts

Last updated 2 May, 2023
14 mins read

Event-Driven Architecture
An event-driven architecture is one in which a system reacts to events that are emitted by other systems. The definition of an event can vary based on the architecture as they will likely be specific to the systems involved.
Let’s pretend that we have two services in our event-driven architecture. We have the PaymentService which handles processing transactions. We also have the NotificationService which sends notifications to users.
In an event-driven architecture, the NotificationService can listen for an event like purchase_complete from the PaymentService and notify a user that the transaction is complete.
This type of architecture consists of three things. There are the event emitters, in our example above the PaymentService is an emitter as it emits a purchase_complete event. Emitters know nothing about who could be listening for their events, in fact, it’s possible that nobody is. While our NotificationService is an event consumer, it reacts to the events that it is listening for. Then there is the conduit between the two which is the channel in which the events are passed.
Event-driven architectures allow for services to be loosely coupled to each other. Each system can be responsible for its domain and emit events when actions occur without ever caring about how those events are being used. Meanwhile, other systems can react to those events to execute logic in their own domains.
The definition of an event is dependent on the system we are building. In our example above, when a transaction completes an event gets emitted. How that event is structured and the conduit in which it is delivered varies depending on what the system is we are building.
That’s event-driven architectures at a high-level. Now let’s think about them in reality by viewing them through the lens of Amazon Web Services.
Thinking about events in AWS
It goes without saying that events are critical to the event-driven architecture.
But, the definition of those events is not strict and can be defined by us to suit what our system needs. For the rest of this post we are going to focus on building our serverless architecture within Amazon Web Services.
In an AWS eco-system, there are already some events defined for us. We can enable events on an S3 bucket when a new file is added. These events can be delivered to other services like SNS, SQS, and AWS Lambda.
We can listen on DynamoDB streams and craft events as operations are performed on our database tables. These events can get processed by AWS Lambda or pushed to Kinesis for other services to further process.
While these are “events” within AWS, they may not always be the events that are applications care about. Instead we could think of these native AWS events as conduits we can leverage to pass our own events between services. We can use the fact that an S3 PUT triggers an event that is passed to an SQS queue.
How exactly? Well, let’s think about our purchase complete event again.
Our PaymentService, writes an invoice to an S3 bucket to signal that the purchase is complete. The drop of that invoice on S3 could send an event to an SQS queue that our NotificationService is watching. Our NotificationService could read that message and then send a notification to the user.
In this scenario, our “event” is the invoice getting written to S3. Our conduit is the native AWS PUT event forwarding a message to SQS. Our services in play aren’t even creating their own events in this situation. Yet we still have an event-driven architecture.
But we could even change that as well. We could have the PaymentService generate a JSON message and send that to an SNS topic that the NotificationService is listening on. That message could be generic and point to the invoice on S3 or something of the like.
Using this pattern we are making the events explicit rather than implicit. The PaymentService in this scenario always pushes events to an SNS topic in a well-defined format like JSON. It doesn’t know, nor should it care, if anyone is listening for those events. The NotificationService subscribes to the topic and processes the ones it cares about.
Like S3 and SQS before, SNS is the conduit that to pass the events along.
Now that we understand the basics of events and conduits that are available to us, let’s build a simple event-driven architecture in AWS that is also 100% serverless.
Let’s Leverage AWS Lambda
We took a look at what defines an event and how those events get delivered via conduit services within AWS. Now let’s put these ideas into practice. We are going to build out a simple architecture within AWS that leverages AWS Lambda.
First, let’s ground ourselves in an example use case where it makes sense to use an event-driven architecture.
We have an application that allows the user to upload files to back them up. These files get stored in an S3 bucket of our choosing. But a feature of our application is that users can do free text searches across the files they have backed up.
Now there are many ways to solve for this use case. One approach as we are going to show here is that we have the upload of a new file event trigger a service that extracts the content from the file. With the extracted content in hand we can send events to other services to insert it into a search database.
To get started we are going to make use of Terraform to provision the AWS S3 bucket where our uploaded files are stored. If you don’t yet have Terraform configured on your machine, get that set up now.
1 2 3 4 5 |
$ mkdir file-upload-extraction $ cd file-upload-extraction $ mkdir common-infrastructure $ cd common-infrastructure $ touch main.tf |
In main.tf let’s add the following infrastructure to create our S3 bucket.
1 2 3 4 5 6 7 8 |
provider "aws" { version = "~> 2.0" region = "us-east-1" } resource "aws_s3_bucket" "file_upload_bucket" { bucket = "file-upload-extraction-example" } |
It’s worth taking a step back here and thinking about the infrastructure for our serverless architecture. In our Terraform template, we define the S3 bucket that holds uploaded files. Notice that we are not configuring the S3 events that will trigger our AWS Lambda functions here.
We are going to make use of Terraform and Serverless Framework together. The goal is to separate the shared infrastructure concerns from individual service ones.
In other words, we use Terraform to define our shared infrastructure, i.e. the bucket where files get uploaded. Then we can use Serverless Framework to define the infrastructure for our extract Lambda function. This allows Terraform to control the common infrastructure. While Serverless controls the specific extraction Lambda function and event trigger.
With that in mind, let’s define our Serverless template. First, we need to configure our Serverless project using the CLI, the AWS Command Line Interface.
1 2 3 |
$ serverless create --template aws-nodejs-typescript --path file-extraction $ cd file-extraction $ npm install |
Now that we have our project defined in Serverless let’s take a look at the infrastructure we need to define in the serverless.yml file.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
service: name: file-extraction # Add the serverless-webpack plugin plugins: - serverless-webpack provider: name: aws runtime: nodejs8.10 functions: hello: handler: handler.extractFile events: - s3: bucket: file-upload-extraction-example event: s3:ObjectCreated:* rules: - prefix: uploads/ existing: true |
Here we are defining the specific infrastructure that will extract content from files that our common AWS S3 bucket receives. The key bit to notice here is the events section defined in our template. We are configuring this Lambda function to be triggered by ObjectCreated events on the prefix uploads/ in our shared bucket, file_upload_extraction_example. The special key, existing, allows us to use an existing bucket (i.e. the one we are defining via Terraform).
Now that we have our shared infrastructure defined in Terraform. Our specific infrastructure defined in Serverless Framework, let’s get everything provisioned. To get started let’s provision our Terraform infrastructure first.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
$ cd common-infrastructure $ terraform init $ terraform apply -auto-approve aws_s3_bucket.file_upload_bucket: Creating... acceleration_status: "" => "" acl: "" => "private" arn: "" => "" bucket: "" => "file-upload-extraction-example" bucket_domain_name: "" => "" bucket_regional_domain_name: "" => "" force_destroy: "" => "false" hosted_zone_id: "" => "" region: "" => "" request_payer: "" => "" versioning.#: "" => "" website_domain: "" => "" website_endpoint: "" => "" aws_s3_bucket.file_upload_bucket: Creation complete after 8s (ID: file-upload-extraction-example) Apply complete! Resources: 1 added, 0 changed, 0 destroyed. |
Cool, our S3 bucket is now present so we can deploy our Serverless Framework template. Before we do that let’s update our handler.ts file to have the following code.
1 2 3 4 5 6 7 |
import { S3Handler } from 'aws-lambda'; import 'source-map-support/register'; export const extractFile: S3Handler = async (event, _context, callback) => { console.log(event) callback() } |
Here we are updating our handler logic to print the S3 event to the console and then return success. This will give us an idea of what exactly is in the S3 event that triggers our Lambda function so that we can create the logic to extract content from the file.
Let’s go ahead and deploy this now via the Serverless CLI.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
$ cd file-extraction $ serverless deploy Serverless: Bundling with Webpack... Time: 1215ms Serverless: Packaging service... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service file-extraction.zip file to S3 (68.58 KB)... Serverless: Uploading custom CloudFormation resources... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... ........................ Serverless: Stack update finished... Service Information service: file-extraction stage: dev region: us-east-1 stack: file-extraction-dev resources: 8 api keys: None endpoints: None functions: hello: file-extraction-dev-hello layers: None |
Awesome, now our initial serverless function is deployed and ready to start processing the first event in our architecture, a file upload. We can confirm that the event notification is configured on our S3 bucket by running this AWS CLI call.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
$ aws s3api get-bucket-notification-configuration --bucket file-upload-extraction-example { "LambdaFunctionConfigurations": [ { "Filter": { "Key": { "FilterRules": [ { "Name": "Prefix", "Value": "uploads/" } ] } }, "LambdaFunctionArn": "arn:aws:lambda:us-east-1:XXXXXXX:function:file-extraction-dev-hello", "Id": "file-extraction-dev-hello-c029bfdd11edac5bdc50a1ac2b6bd0c8", "Events": [ "s3:ObjectCreated:*" ] } ] } |
We have an event notification configured on our bucket at the uploads/ prefix. We can confirm that our function gets triggered by uploading a file to that prefix via the CLI.
1 2 3 |
$ echo ‘this is a test’ > test.txt $ aws s3 cp test.txt s3://file-upload-extraction-example/uploads/ upload: ./test.txt to s3://file-upload-extraction-example/uploads/test.txt |
Our file was successfully uploaded, but did our Lambda function get triggered via our upload event? We can check the logs in AWS CloudWatch for that.
1 2 3 |
$ aws logs describe-log-streams --log-group-name /aws/lambda/file-extraction-dev-hello // grab the logStreamName value for the next command $ aws logs get-log-events --log-group-name /aws/lambda/file-extraction-dev-hello --log-stream-name 2019/07/16/[$LATEST]3f1c23aaecd24f8cbfc140fa14dfa896 |
After grabbing the logs from CloudWatch via the CLI we should see that our S3 event was successfully logged.
Awesome! We have a functioning serverless event driven pipeline. Now let’s add the actual logic to extract the file content. We are going to do that by grabbing the S3 bucket and key from the event. With those two pieces of information we can read the content of the file.
Here is the code in our handler.ts that does this.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import { S3Handler, S3Event } from 'aws-lambda'; import 'source-map-support/register'; import {S3} from "aws-sdk"; import { GetObjectRequest } from 'aws-sdk/clients/s3'; export const extractFile: S3Handler = async (event: S3Event, _context, callback) => { const s3Client = new S3() const getParams: GetObjectRequest = { Bucket: event.Records[0].s3.bucket.name, Key: event.Records[0].s3.object.key } var contentObj = await s3Client.getObject(getParams).promise() console.log(contentObj.Body.toString()) callback() } |
Here we are grabbing the file from S3 via the event record that triggered our Lambda function. Once we have the content on the file, we are logging it to the console for now so that we can confirm this is working as expected.
Before we can test this out we need to update our serverless.yaml once more. Our AWS Lambda function is going to download the file from the bucket that triggers the event. To do that we need to give our function the IAM permissions to download the file. We do that by adding an additional IAM policy to our serverless configuration, our provider section should now look like this.
1 2 3 4 5 6 7 8 9 10 |
provider: name: aws runtime: nodejs8.10 iamRoleStatements: - Effect: 'Allow' Action: - 's3:GetObject' - 's3:PutObject' Resource: - "arn:aws:s3:::file-upload-extraction-example/*" |
This will allow our Lambda function to get objects from our AWS S3 bucket as well as write new objects to it, more on that soon. Let’s deploy this once more so that we can test that we pull the content out as expected.
1 2 3 4 5 |
$ serverless deploy ....wait for deploy to finish... $ echo ‘this is another test’ > test_2.txt $ aws s3 cp test_2.txt s3://file-upload-extraction-example/uploads/ upload: ./test_2.txt to s3://file-upload-extraction-example/uploads/test_2.txt |
Now if we check our CloudWatch Logs either via the CLI or the console, we should see the contents of our file are logged out.
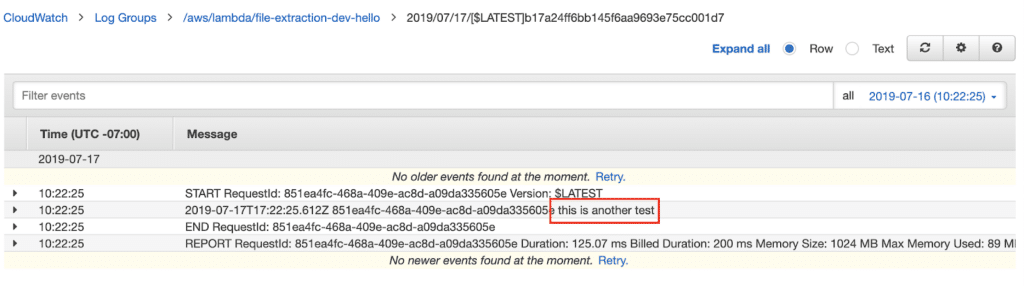
Let’s take a step back and check where we are at with our serverless event driven pipeline now.
- We have an S3 bucket where files from our users get uploaded.
- When a new file gets uploaded, an event is passed to our Lambda function that is listening on the
uploads/prefix. - Our AWS Lambda function grabs the bucket and key from the event. It then grabs the file and logs the contents of the file to the console.
At this point we have a simple event driven serverless pipeline. It is using the native events for S3 buckets to trigger a Lambda function that is listening on a key prefix. This has incredible scalability because each file upload creates a new invocation of our Lambda function. It also has the scale-to-zero property, if no uploads come in, no Lambdas are launched, and thus we don’t pay for any compute.
Now it’s time to start thinking about the next step in our pipeline, the service that receives the content of the file to insert it into a search database. We aren’t going to go through the full process of inserting into a search database. Instead we are going to focus on the conduit and event between our current service and that insertion service.
To simplify things, let’s use the same conduit we are already using, S3. We are going to write another event to S3 from our current service that contains our extracted content.
We can add this to our current serverless.yaml file by adding another function handler with a different event section. Here is what our functions section should look like now.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
functions: extract-content: handler: handler.extractFile events: - s3: existing: true bucket: file-upload-extraction-example event: s3:ObjectCreated:* rules: - prefix: uploads/ insert-content: handler: handler.insertContent events: - s3: existing: true bucket: file-upload-extraction-example event: s3:ObjectCreated:* rules: - prefix: extracted/ |
Here we have added an another function, insert-content, which handles create events at the prefix extracted/ in our bucket. Also notice that it this function has a different handler, handler.insertContent. We can add this function to our existing handler file. For our purposes we will print out the event to the console to confirm we received it.
1 2 3 4 |
export const insertContent: S3Handler = async (event: S3Event, _context, callback) => { console.log(event.Records[0].s3.object.key) callback() } |
Cool, we have the next function in our serverless event-driven pipeline defined. Let’s update our extractFile function to write the extracted content to our extracted/ prefix which will trigger our new Amazon Lambda function.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
export const extractFile: S3Handler = async (event: S3Event, _context, callback) => { const s3Client = new S3() const getParams: GetObjectRequest = { Bucket: event.Records[0].s3.bucket.name, Key: event.Records[0].s3.object.key } var contentObj = await s3Client.getObject(getParams).promise() const putKey = event.Records[0].s3.object.key.split('/').slice(1).join('/') const putParams: PutObjectRequest = { Bucket: event.Records[0].s3.bucket.name, Key: `extracted/${putKey}`, Body: JSON.stringify({ ExtractedDate: Date.now(), Content: contentObj.Body }) } await s3Client.putObject(putParams).promise() callback() } |
The change we have made here is that after we have extracted the content from the file we write a new object to our S3 bucket. In fact we write a new JSON object to the same named file at extracted/ prefix with the content and the date we extracted the content. Once we write that file to our prefix it should trigger our new insertContent function.
Let’s see it in action by deploying our event-driven pipeline.
1 2 3 4 5 |
$ serverless deploy ....wait for deploy to finish... $ echo ‘this is a full test’ > test_3.txt $ aws s3 cp test_3.txt s3://file-upload-extraction-example/uploads/ upload: ./test_3.txt to s3://file-upload-extraction-example/uploads/test_3.txt |
We should expect the file test_3.txt to trigger our extract content function. It will pull the content from the file and write a new JSON event to our extracted/ prefix. That triggers our new insert function where we are logging out the key associated with the event.
We can confirm that our extract content function worked as expected by checking the S3 bucket for our file at the extracted/ prefix.
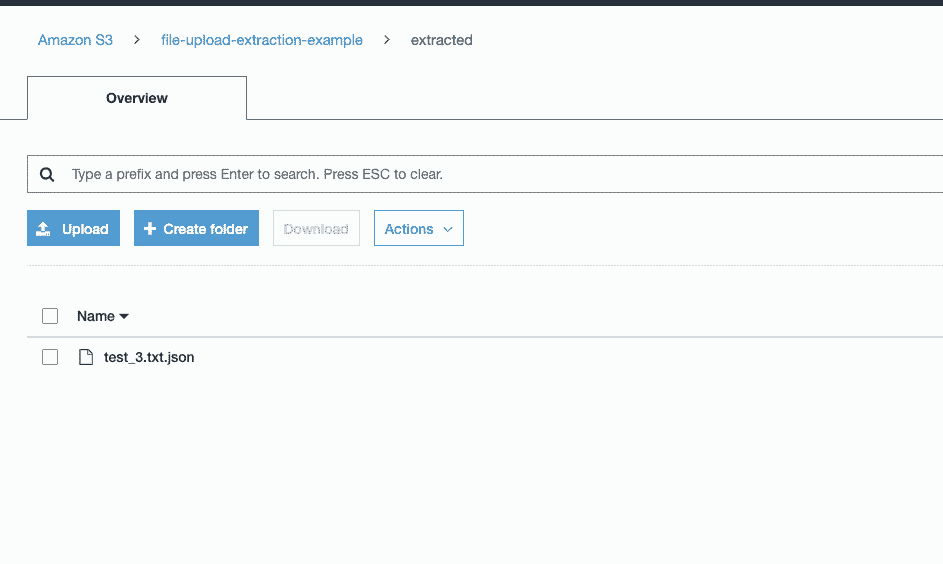
Awesome our serverless event-driven pipeline in AWS is working as expected! Let’s take a step back and recap everything we just built.
What did we just build?
We made it to the end, but what exactly did we build? Let’s recap.
At the start of this post we started thinking about event-driven architectures. These types of systems react to events that emitted by other systems. We talked a bit about the definition of events and their delivery via conduits.
With that understanding we took a look at what events look like in Amazon Web Services. There are lots of events that are native to AWS that are useful for triggering our own processing. These events can also be event conduits for us to deliver our own events. This allowed us to build a serverless event-driven pipeline in AWS.
When a file upload lands in an S3 bucket at the uploads/ prefix, we kick off our pipeline. An AWS event triggers our extract content Lambda function that is listening on that prefix. That service then extracts the content from the file by reacting to the upload event. It doesn’t need to care how the event got triggered or who completed the operation. It knows a file upload landed at the prefix, so it handles the job of extracting the content.
Once it has extracted the content that service writes a new event to the extracted/ prefix in the same S3 bucket. This is a custom event that contains the content of the upload as well as the date it got extracted. In this scenario we are using S3 as a conduit to deliver our custom event.
The drop of this event at the extracted/ prefix triggers the next service in our pipeline, the insert content function. It reacts to a new event showing up at the prefix it is watching. It is now free to do what it needs to do, download the file, grab the content, and insert it into a search database of some kind.
Pretty cool right? Yeah it is! Let’s think about some of the benefits and potential downsides this architecture enables.
Benefits and Tradeoffs Of The Event-Driven Architecture
The first benefit that jumps out when it comes event-driven architectures is that they are relatively decoupled. Each step in the event-driven pipeline responds to an event, does it’s work, and emits its results. Others in the pipeline can be listening for those results to kick off their work.
This doesn’t mean you can’t create coupled event-driven pipelines, you can. In fact our example could head that direction because of the custom event we are writing our to the extracted/ prefix. This has some coupling because the next step in the pipeline needs to know what this event looks like to grab the content.
The next benefit is the amount of distributed compute power we get with this architecture. Each event triggers a new AWS Lambda function which launches to react to that specific event. Meaning we could be process thousands upon thousands of uploads concurrently.
Distributed computing is fantastic, but it comes with a lot of costs that shouldn’t be ignored. Debugging becomes harder, logging becomes more verbose, knowing where each file is in the pipeline is tricky. It is a great thing to scale out and process many things in parallel, but it also introduces new complexities.
The last benefit I want to call out is the fact that this entire pipeline scales to zero. If there are no file uploads, the pipeline isn’t running and we aren’t paying for it. This isn’t a benefit of event-driven architectures but more of a benefit of building it serverless.
That said, this pipeline could become very expensive to run in a serverless world. Wait what? Yes, the world of serverless is more pricey as the throughput of our systems is more constant and less spikey. In our example, if a user was uploading a file every minute of every day our pipeline would be running non stop. Meaning it would never scale to zero. Using a product like CloudForecast can help you monitor cost and ensure this pipeline cost does not spiral out of control.
Conclusion
In this post we explored the general concepts associated with event-driven architectures. We then explored how those concepts manifest in a cloud world like Amazon Web Services. With those two pieces covered we were able to build out a simple serverless event-driven pipeline that reacts to events happening in S3. This allowed us to explore how S3 events are both conduits but also events that can trigger other services in our pipeline.
We thought a bit about some of the benefits this architecture can provide as well as some of the downsides or tradeoffs that it introduces. It isn’t an architecture that works for everything but it has some nice benefits that make it work for several things.
If you have any questions about event-driven architectures or anything related to Amazon Web Services, hit me up on Twitter @kylegalbraith or drop a message below. Also checkout my weekly Learn by Doing newsletter or my Learn AWS By Using It course to learn even more about the cloud, coding, and DevOps.
If you have questions about CloudForecast and how it can help your organization monitor AWS cost, feel free to ping Tony: [email protected]
Want to try CloudForecast? Sign up today and get started with a risk-free 30 day free trial. No credit card required.
Manage, track, and report your AWS spending in seconds — not hours
CloudForecast’s focused daily AWS cost monitoring reports to help busy engineering teams understand their AWS costs, rapidly respond to any overspends, and promote opportunities to save costs.
Monitor & Manage AWS Cost in Seconds — Not Hours
CloudForecast makes the tedious work of AWS cost monitoring less tedious.
More from CloudForecast




AWS cost management is easy with CloudForecast
We would love to learn more about the problems you are facing around AWS cost. Connect with us directly and we’ll schedule a time to chat!
